들어가며
이번 1편은 전체 이관 과정 중 이관 전 클러스터의 현재 상태와, 컨트롤플레인 이관 전에 선행해야 할 점검/설정 항목을 다루려고 한다. 해당 클러스터를 구축하고 꽤 시간이 지난 상태였기 때문에 현 상태를 정확히 파악하는 과정이 필수였다. 현재 상태를 모르면 이관 중 발생하는 장애가 기존 이슈인지, 이관으로 유발된 이슈인지 분리하기 어려워지고, 원인 파악이 늦어지면서 절차를 되돌려 여러 방법을 반복 시도하게 되어 시간 리소스 낭비로 이어질 수 있다. 이를 방지하기 위해 기존 상태를 잘 살피고, 이에 따른 전략을 세우고, 그 후에 이관을 실행하려고한다. 실제 승격/복구 디테일은 다음 편들에서 다뤄보겠다.
전체 구조
점검 당시 클러스터 전체 구조는 아래 차트와 같았다. 클러스터는 마스터 1대와 워커 3대로 구성되어 있었고, 노드 간 통신은 WireGuard(wg0, 10.99.0.x) 기반, 파드간 통신은 flannel(CNI)으로 이루어졌다. 차트 기준으로 기존 마스터 노드는 ilhaeng-web-server였으며 내부 IP로는 10.99.0.1, 공인 IP로는 175.45.194.233를 사용했다. 승격 후보 노드는 s199cd8e78db였고 내부 IP로는 10.99.0.2(wg0), 공인 IP로는 211.188.60.224를 사용했다.
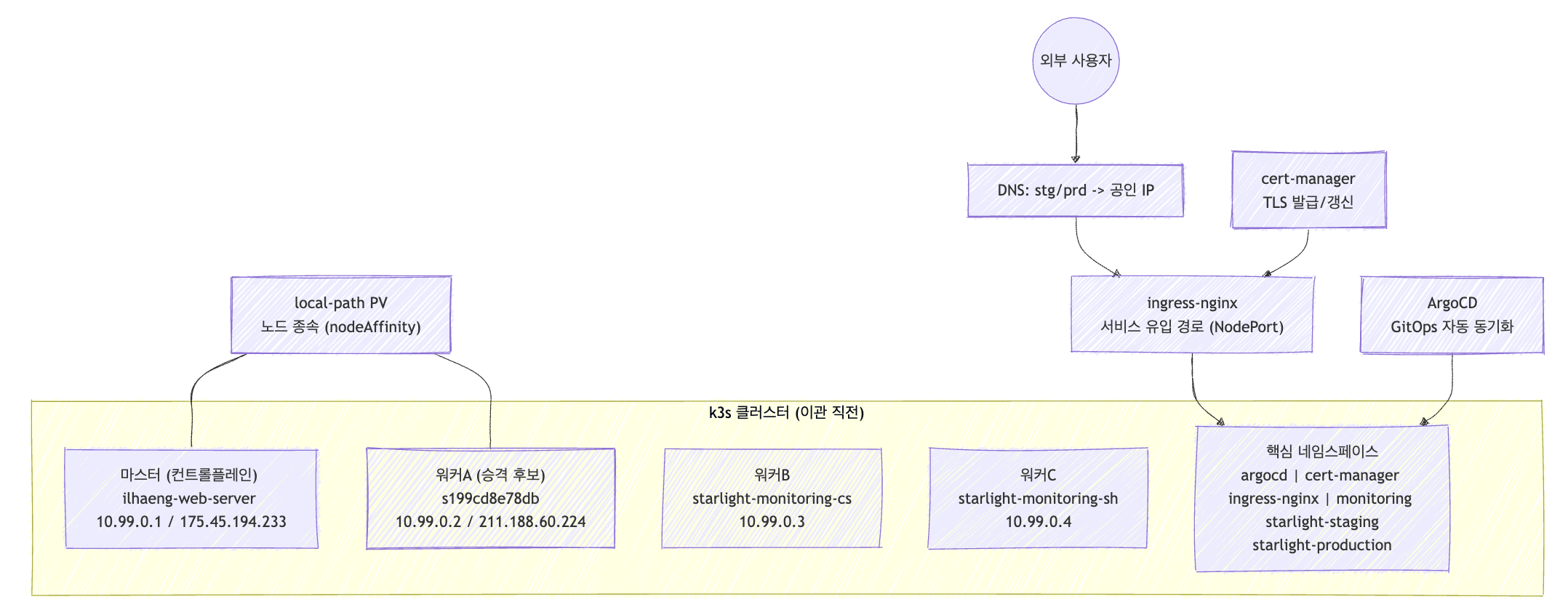
사전 점검
마스터 이관은 일단 해보자로 들어가면 복구 범위가 급격히 커진다. 최소한 아래는 이관 전에 확정해야 했다.
- 지금 클러스터가 안정 상태인지
- 승격 후보 노드가 컨트롤플레인까지 감당할 수 있는지
- 스토리지가 특정 노드에 묶여 있는지(local-path)
- GitOps가 수동 변경을 되돌릴 가능성이 있는지(ArgoCD self-heal)
1) 클러스터 접근/컨텍스트 확인
먼저 내가 지금 어떤 클러스터를 보고 있는가를 확인했다. current-context는 반드시 의도한 컨텍스트(수정 대상 컨텍스트)여야 한다.
kubectl config current-context
kubectl config get-contexts
kubectl cluster-info2) 노드/네임스페이스/파드 스냅샷
리소스 확인 결과 노드 CPU 사용률은 2~9%, 메모리 사용률은 42~63% 수준이었다. 이 수치만 놓고 보면 즉시 증설 없이도 기존 워커 노드를 컨트롤플레인으로 승격해 이관을 시도할 수 있는 상태라고 판단했다. 다만 이관 과정에서는 k3s server/etcd 기동, 워크로드 재스케줄링, 파드 재시작이 겹치면서 메모리 사용량이 순간적으로 치솟을 수 있다. 따라서 작업 중에는 메모리 추이를 지속적으로 관찰하고, 급격한 스파이크가 발생하지 않도록 주의하면서 이관을 진행했다.
kubectl get nodes -o wide
kubectl get ns
kubectl get pods -A -o wide3) 노드별 여유 리소스 확인
4개의 노드가 모두 Ready 상태인지, 컨트롤플레인이 실제로 어느 노드에 붙어 있는지, 그리고 주요 네임스페이스가 정상적으로 운영 중인지 먼저 확인했다. 이관 전에 이미 노드나 파드에 문제가 있는 상태라면, 기존 이슈와 이관 과정에서 발생한 이슈가 뒤섞여 원인 분리가 어려워진다. 그래서 이관 작업에 들어가기 전, 먼저 현재 상태를 기준선(baseline)으로 고정할 수 있도록 클러스터를 가능한 정상 상태로 정리한 뒤 이관을 진행하는 방향으로 잡았다.
kubectl top nodes
kubectl top pods -A --sort-by=cpu
kubectl top pods -A --sort-by=memory
리소스 정리
노드를 한 대 줄이는 만큼, 기존 리소스 중 불필요한 워크로드는 먼저 제거해 메모리와 실행 여유를 확보하는 편이 합리적이라고 판단했다. 특히 더 이상 서비스하지 않는 구성은 파드 단위 정리보다 네임스페이스 단위로 제거하는 것이 영향 범위를 명확히 하면서도 정리 효과가 크다. 이번 작업에서도 운영 대상에서 제외된 리소스는 네임스페이스 자체를 삭제하는 방식으로 정리해, 이관 과정에서의 노이즈를 줄이고 클러스터 여유분을 확보했다.
1 ) 리소스 확인 및 삭제
kubectl get all -n ncareer
kubectl get pvc -n ncareer
kubectl get ingress -n ncareer
kubectl delete namespace ncareer
kubectl get ns ncareer2 ) 삭제 확인 및 재삭제
위 결과로 삭제 현황을 확인했지만, 삭제 직후 파드가 다시 생성되는 것을 확인할 수 있었다. 기존 배포 구조가 ArgoCD 기반 GitOps였기 때문에, ArgoCD가 Git에 정의된 desired state를 유지하려고 리소스를 자동으로 복구(self-heal)한 것으로 판단했다. 따라서 단순히 네임스페이스/리소스를 삭제하는 방식이 아니라, ArgoCD의 Application(및 관련 정의)을 먼저 제거한 뒤에 네임스페이스를 재삭제하는 흐름으로 전환해 완전한 정리가 이루어지도록 했다.
kubectl -n argocd get applications.argoproj.io
kubectl -n argocd delete applications.argoproj.io ncareer
kubectl -n argocd delete applications.argoproj.io ncareer-root
kubectl delete namespace ncareer
kubectl get ns ncareer
datastore 모드 확정(etcd / sqlite)
k3s 마스터 이관 전략은 datastore 모드(etcd vs sqlite)에 따라 완전히 달라진다. 컨트롤플레인이 관리하는 클러스터 상태(노드/파드/리소스 메타데이터)가 어디에, 어떤 방식으로 저장되는지가 달라지기 때문이다. SQLite 기반이라면 상태가 단일 DB 파일(state.db) 중심으로 유지되는 성격이 강해서, 단순히 워커를 server로 승격하는 방식만으로는 기존 상태를 안전하게 이어받기 어렵고, 결국 기존 상태를 어떻게 보존·복구할지가 이관의 핵심이 된다. 반대로 embedded etcd 기반이라면 k3s server를 추가해 컨트롤플레인/etcd 멤버를 확장하고, 이후 기존 마스터 멤버를 제거하는 식으로 멤버십과 쿼럼을 관리하는 이관 흐름을 가져갈 수 있다.
1) 설정/토큰/노드 정보 수집
기존 마스터노드에서는 control-plane이 어떤 IP/인터페이스로 advertise 되는지를 먼저 고정했고, 조인을 위해 노드 token도 확인했다. 승격 후보 에서는 ip -br a로 네트워크 인터페이스를 확인했다. 클러스터 노드 간 통신은 WireGuard wg0(10.99.0.x) 대역을 사용 중이었고, 기존 마스터도 10.99.0.1을 control-plane 주소로 광고하고 있어, 이관에서도 control-plane 기준 대역을 10.99.0.x로 유지해야겠다고 생각하였다.
# 기존 마스터 정보 확인
sudo cat /etc/rancher/k3s/config.yaml
sudo systemctl cat k3s
sudo cat /var/lib/rancher/k3s/server/token
sudo k3s kubectl get nodes -o wide
# 승격 후보 인터페이스 확인
ip -br a2) etcd 사용 여부를 “동작 증거”로 검증
디렉터리에 etcd 폴더가 존재해 처음에는 etcd 기반으로 운영 중이라고 판단할 수 있었지만, 디렉터리 존재만으로는 실제 datastore 모드를 확정할 수 없었다. 그래서 k3s etcd-snapshot 같은 동작을 기반으로 확인을 먼저 수행했다. 그 결과 etcd datastore disabled 에러가 발생했고, 이는 당시 상태에서 etcd 기준 절차로 이관을 바로 진행하면 위험하다는 의미였다. 따라서 이관에 앞서 datastore 모드를 먼저 확정·정리하는 단계가 필요했다.
sudo k3s etcd-snapshot save --name pre-move-$(date +%F-%H%M)
sudo k3s etcd-snapshot ls3) 기존 마스터를 cluster-init 기반 embedded etcd로 전환
기존 마스터에서 etcd datastore disabled가 확인됐기 때문에, 이관 전에 datastore 모드를 etcd 기준으로 정리하는 작업이 필요했다. 기존 마스터에서 백업을 선행한 뒤 cluster-init 기반으로 embedded etcd를 실제 동작 상태로 전환해 datastore 모드를 확정했다.
# k3s를 정지
sudo systemctl stop k3s
# k3s 설정 디렉터리를 타임스탬프를 붙여 백업했다.
sudo cp -a /etc/rancher/k3s /etc/rancher/k3s.bak.$(date +%F-%H%M)
# 서버 데이터 디렉터리를 백업
sudo cp -a /var/lib/rancher/k3s/server /var/lib/rancher/k3s/server.bak.$(date +%F-%H%M)
# embedded etcd 클러스터를 초기화
grep -n '^cluster-init:' /etc/rancher/k3s/config.yaml || echo 'cluster-init: true' | sudo tee -a /etc/rancher/k3s/config.yaml
# k3s를 재시작
sudo systemctl start k3s
# 노드 역할이 control-plane,etcd,master로 바뀌었는지 확인
sudo k3s kubectl get nodes -o wide
# datastore가 etcd로 활성화되어있는지 살핌
sudo k3s etcd-snapshot save --name after-etcd-$(date +%F-%H%M)'Infra' 카테고리의 다른 글
| k3s 마스터 노드 변경하기(0) - 배경 및 결론 (1) | 2026.02.21 |
|---|---|
| Cronjob을 활용한 기업정보 크롤링 파이프라인 구축하기(1) - 기능 구현 (0) | 2025.09.07 |
| ArgoCD UI Permission Error 해결 (3) | 2025.08.24 |
| EKS 클러스터 및 노드 그룹 생성, Kubectl 설치 및 연결 (0) | 2025.06.24 |
| 쿠버네티스 리소스 관리 pod 과 deployment (2) | 2025.06.22 |